
01 系统总体架构
船舶与海洋大数据分析服务的建设内容和任务主要有海洋数据引接、数据存储、数据分析、可视化子系统、数据服务与应用等研究内容。系统的总体架构如图1所示。
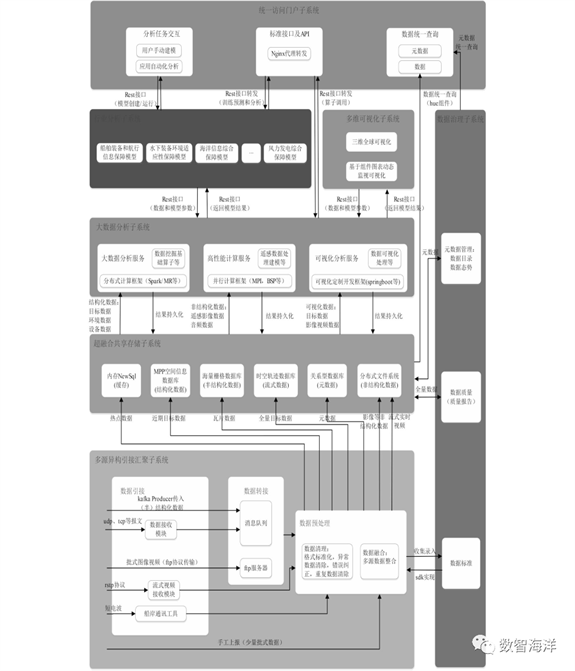
图 1 海洋大数据智能分析平台总体架构
02 接口设计
2.1 外部接口设计
船舶与海洋大数据分析服务主要包括引接汇聚子系统、数据治理子系统、超融合共享存储子系统、大数据分析子系统、行业分析子系统、统一访问门户子系统6个部分。其中外部接口包括引接汇聚子系统与源数据的接口、大数据分析子系统与外部应用系统的接口,其外部接口如图2所示。
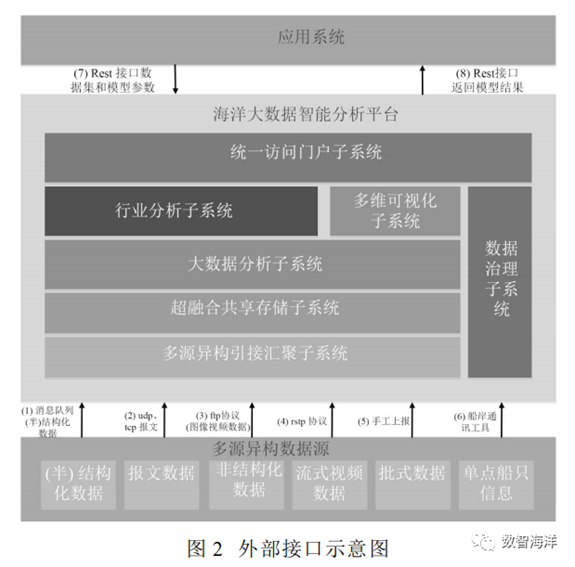
2.2 内部接口设计
船舶与海洋大数据分析服务的内部接口主要包括引接汇聚子系统与超融合共享存储子系统的接口、引接汇聚子系统与数据治理子系统的接口、超融合共享存储子系统与数据治理子系统的接口、超融合共享存储子系统与大数据分析子系统的接口、大数据分析子系统与行业分析子系统的接口,内部接口如图3所示。
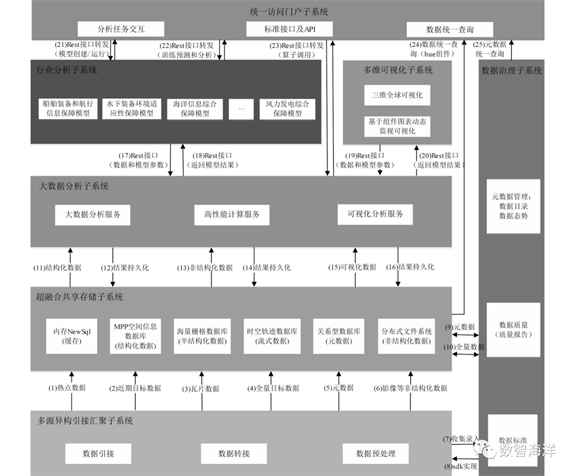
图 3 内部接口示意图
03 业务流程
3.1 用户手动建模训练
用户手动建模训练是用户使用大数据分析服务进行自己业务的模型搭建,对数据进行分析和处理的流程。根据具体需求,用户可以自定义算子然后再通过拖拽算子的方式手动构建模型。操作流程如图4所示。
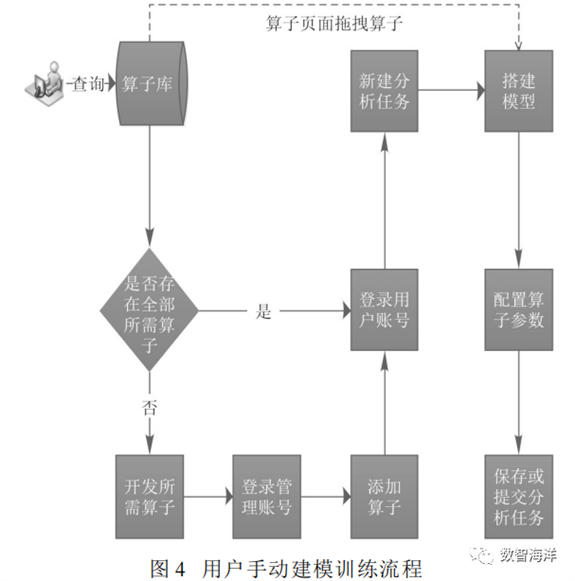
3.2 应用自动化训练
大数据分析服务对外提供统一的Rest接口,主要有训练和预测、分析和算子调用3种应用场景。
1)训练和预测
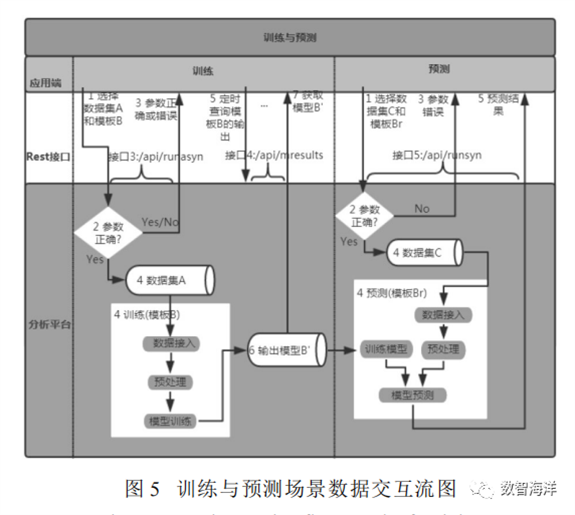
训练时,应用端通过接口1和接口2得到数据集和模板列表,选择数据集和模板;然后通过接口3提交返回的数据集id和模板id;分析服务接收后进行参数校验,返回参数正确或者错误,同时启动模板调用数据,进行模型训练;最后通过接口4定时查询训练模型结果是否产生。分析服务去数据库中查询结果,返回结果未生成,或者返回训练好的模型。
预测时,应用端通过接口1和接口2获取数据集和模板列表,选择数据集和模板;然后通过接口5提交返回的数据集id和模板id;分析服务接收后进行参数校验,参数错误则返回参数错误信息,正确则调用模板,输入数据集和训练好的模型,得到预测结果并返回给应用端。训练与预测场景的数据交互流如图5所示。
2)分析
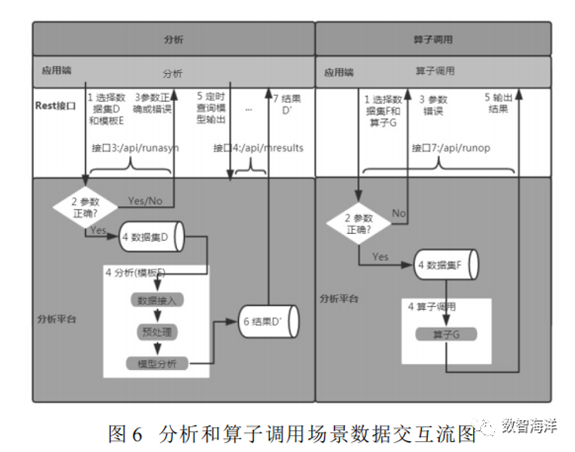
应用端通过接口1和接口2获取数据集和模板列表;然后通过接口3发送数据集id和模板id;分析服务检查参数是否正确,并返回正确与否,如果参数正确,调用模板和数据集进行分析;最后通过接口4定时查询分析结果是否产生。分析服务返回分析结果未产生信息,或者返回分析结果。分析场景数据流如图6(左)所示。
3)算子调用
应用端调用接口1和接口6获取数据集和算子列表,选择数据集和算子;调用接口7发送数据集id和算子id;分析服务检查参数是否正确,错误则返回参数错误,正确则调用算子和数据集,运行后的结果返回给应用端。算子调用数据流如图6(右)所示。
04 子系统设计
4.1 多源异构引接汇聚子系统
多源异构引接汇聚子系统主要由数据引接、数据转接和数据预处理3部分组成,用于将各种实时或者历史多源异构数据接入到大数据分析服务的存储模块中。数据转接模块将数据转存到kafka组件和ftp文件系统里实现本地持久化;数据预处理模块将暂存的数据获取后经过数据清理和数据融合,得到格式规范的数据,然后存入超融合共享存储子系统。多源异构引接汇聚子系统架构如图7所示。

4.2 海洋大数据治理子系统
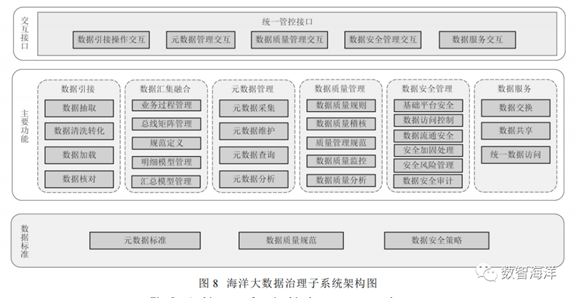
海洋大数据治理子系统包含元数据管理、数据质量管理、数据标准等,用于提升异构环境下海洋数据(海洋环境、海洋目标、风力发电设备运行数据、船舶动力数据、水下装备运行效能数据、JJ适配性数据、海洋资源探测)的管理水平和使用效率。海洋大数据治理子系统架构图如图8所示。
4.3 超融合共享存储子系统
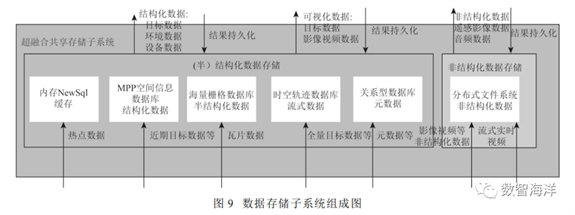
超融合共享存储子系统针对多源异构数据在存储上的多样性特征,实现了对海量多源数据的引接、存储、管理和组织。其底层支持结构化、半结构化数据的承载组织,将结构化数据存储在本地关系数据库或分布式存储系统中,将非结构化数据存储在共享文件系统中,并对数据的存储进行优化,使数据存储子系统具备并发访问性能及存储规模的强可扩展性。数据存储子系统架构如图9所示。
4.4 海洋大数据分析子系统
海洋大数据分析子系统对多元异构数据进行分析建模处理,主要包括3个部分:大数据分析服务、高性能计算服务和可视化分析服务。
1) 大数据分析服务
大数据分析服务是一个自助式建模分析服务,利用数据挖掘、机器学习、包括深度神经网络等分析技术对相应数据集进行挖掘建模。服务架构主要分为3层,最底层的是一个由HDFS,MapReduce和Spark等大数据框架组成的一个大数据引擎;中间层是一个算子库,服务提供高效丰富、支持分布式的算子,并提供统一的对外提供服务接口方式,支持上层应用;最上层是一个大数据可视化建模应用层,用户可通过创建、配置、提交和监督来搭建自己的业务逻辑和分析模型,并且支持列表、折线图、柱状图和饼图等多种形式的分析结果展示及保存。
大数据分析服务的架构如图10所示。

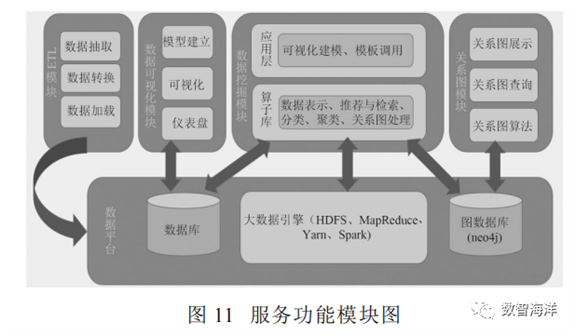
大数据分析服务模块由数据管理、分析任务管理、系统管理、ETL模块、算子库、数据可视化模块构成,如图11所示。
2) 高性能计算服务
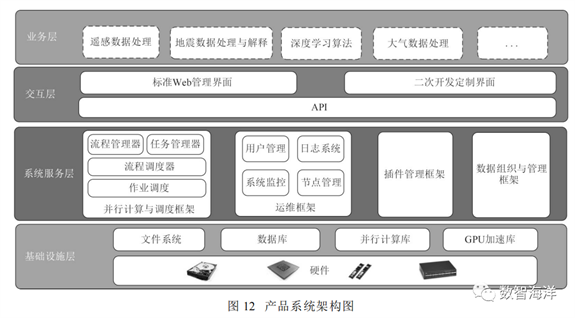
高性能计算(HPC)服务是一个软硬件一体的架构,采用存算一体化、混合异构计算等多种并行策略,结合深度学习等手段实现海量数据全自动、高效率、高精度的快速处理和智能分析解译,实现海量数据快速处理和实时响应,如图12所示。
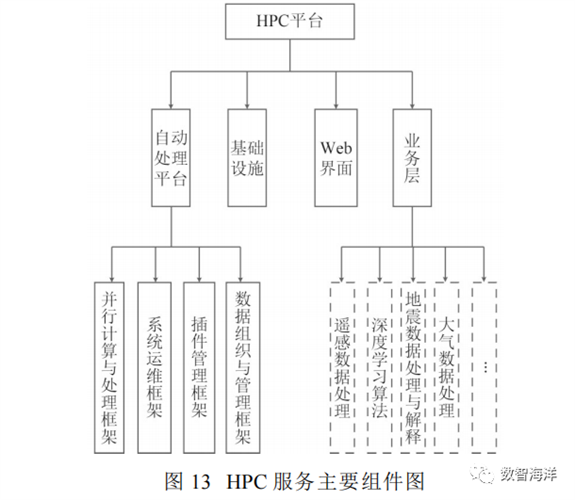
HPC服务的主要组件如图13所示。
3) 可视化分析服务
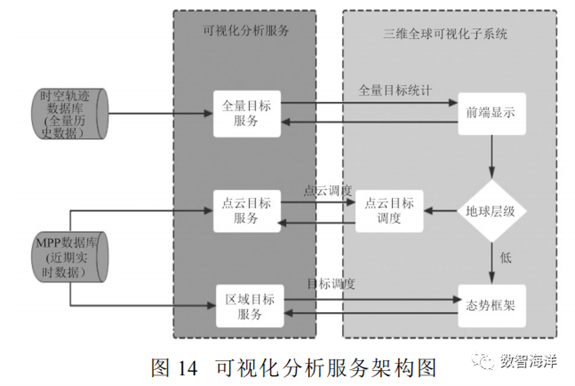
可视化分析服务为三维全球可视化子系统提供数据处理的功能,服务架构如图14所示。
4.5 行业分析子系统
通过数据挖掘、分析处理、云计算等技术,以多源异构海洋与船舶数据的存储与管理、海洋与船舶高通量实时流数据处理、目标关联与异常预警、海上航线智能规划、船舶动力装备故障自动诊断与趋势分析、海洋与船舶动态目标高效渲染及实时展示等实际应用技术,形成船舶装备和航行信息保障、水下装备环境适应性保障、军民融合海洋信息综合保障以及风力发电综合保障等行业应用专用分析模型库,为同类行业应用研制提供可复用的行业专用模型资源保障。
4.6 多维数据可视化子系统
1)基于组件图表动态监视可视化
在分布式计算的基础上,封装可视化分析算子、可视化图形组件、可视化交互组件等,使得所有分析功能、展示方式以拖拽式开发,所见即所得。利用PC机、大屏等终端,通过浏览器即可实现访问和分享。总体架构如图15所示。

2)三维全球可视化
三维全球可视化子系统基于地理空间可视化技术,采用“服务+插件”的架构,封装标准的三维渲染可视化引擎,实现数据、行业产品数据的接入、渲染、分析和可视化功能。三维全球可视化子系统包括三维可视化支撑、三维基础应用和业务数据可视化3个模块组成,如图16所示。
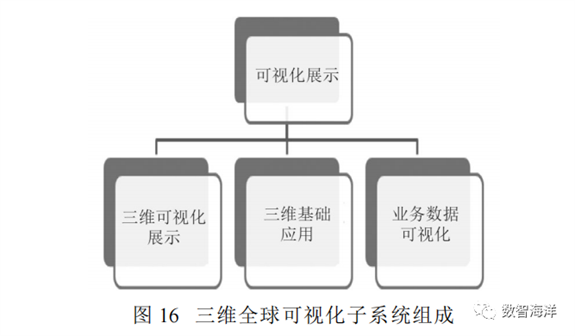
可视化展示子系统服务以GEOVIS iExplorer空天大数据可视化服务为基础,其架构主要包括引擎层、框架层和应用层,如图17所示。
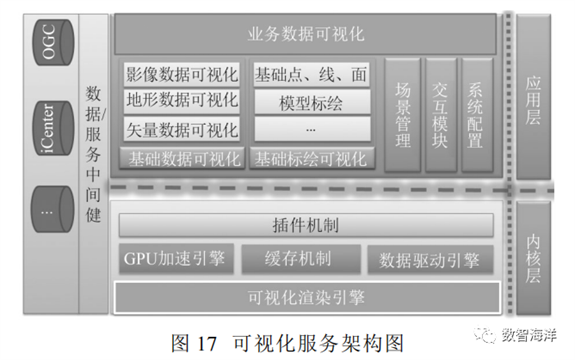
其中引擎层用于创建三维、实现各种数据、符号、图形等在三维球上绘制;服务层实现框架集成、界面配置、工具扩展、数据调度、交互控制以及数据缓存优化机制等;应用层在引擎层、服务层的基础上,构建基础应用,实现了基础数据可视化、专题数据可视化、空间分析、基础标绘等功能,以及在此基础上构建应用系统的能力。
4.7 统一访问门户子系统
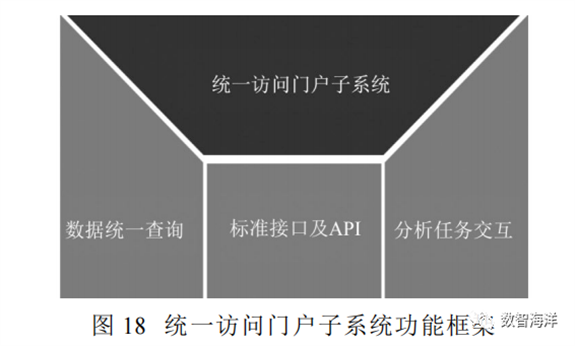
统一访问门户平台将各种分散的、异构的常用应用和数据资源集成到信息管理平台之上,并以统一的用户界面提供给用户,为用户提供一个支持信息访问、传递、以及协作化一站式个性化服务的统一门户平台。统一访问门户子系统可实现数据统一查询、分析任务交互和标准接口及API等服务,如图18所示。
05 关键技术及解决途径
5.1 多源异构数据超融合共享存储
1) 结构化数据存储
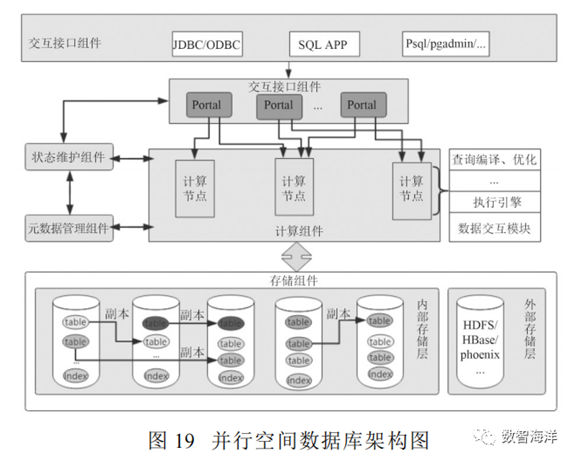
大规模并行空间信息数据库通过MPP架构实现了数据的分载及计算的并行加速;同时通过对传统关系数据库计算引擎扩展,可内置支持对GIS及空间数据的丰富计算函数UDF,同时在语法上支持SQL标准,并兼容OLAP即席分析模式。并行空间数据库架构分层由交互接口组件、状态维护组件、元数据管理组件、计算组件和存储组件组成,如图19所示。
2) 非结构化数据存储
非结构化数据的存储通过超融合共享存储系统实现,其主要提供分布式文件系统功能。用来存储大规模遥感影像、音视频、中间处理结果数据、第三方数据源等非结构化数据,同时还可作为大规模并行空间信息数据库、海量栅格数据库、历史轨迹数据库及第三方Hadoop及Spark等大数据计算服务的底层存储,与文件存储拉通,共享命名空间及存储资源池,形成同一套硬件支撑多个应用出口的融合存储能力。
3) 半结构化数据存储
对于专题数据库中大量的文本数据、消息类数据、日志数据、配置数据等弱结构化数据或freeschema类数据,其存储格式可为文本文件、xml文件或json数据串,相比数据库表其数据格式更为灵活,相比音视频、图片等非结构化数据其又是可解析的。针对此类广泛存在的半结构化数据,本项目采用分布式KV列式数据库进行存储。本数据库技术优势主要体现在多维索引SQL适配上,图20为KV数据库具备的关键技术特性。

5.2 高通量实时流数据处理
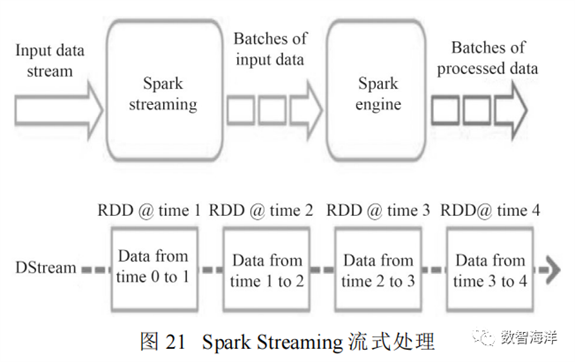
使用Spark Streaming分布式的大数据实时计算框架,提供动态、高吞吐量的、可容错的流式数据处理。可以从多个数据Kafka,Flume,Kinesis,Twitter,Tcp scokets中获取数据,然后使用复杂的算法和高级的函数算子如map,reduce,join,window,进行数据处理加工。最后可以将处理后的数据输出到文件系统,数据库,和可视化界面,同样也可以在数据流上使用机器学习和图形计算算法。Spark Streaming同Spark sql一样在核心RDD上封装一种数据集DStream,用于适应实时计算的特点,类似于Spark sql的Dataset和DataFrame用于方便交互式查询操作,如图21所示。
5.3 高并发接口访问保障
高并发接口访问保障的实现通过2个层面来实现,一个是Nginx对访问接口的负载均衡管理,另一个是并发多线程处理任务机制。
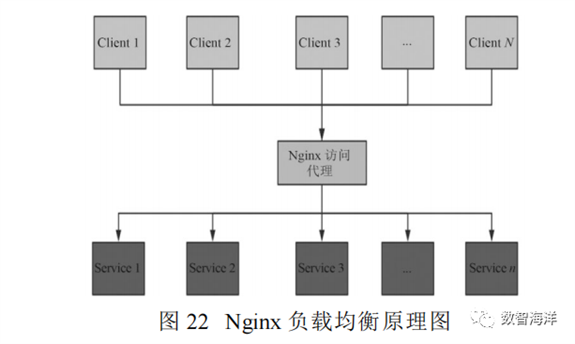
1)Nginx负载均衡
Nginx动态负载均衡通过对于后端接口服务集群的状态监测,量化不同接口服务的性能差异来周期性调整服务器的比重,实现访问接口分配权重的动态调整。负载均衡的原理如图22所示。
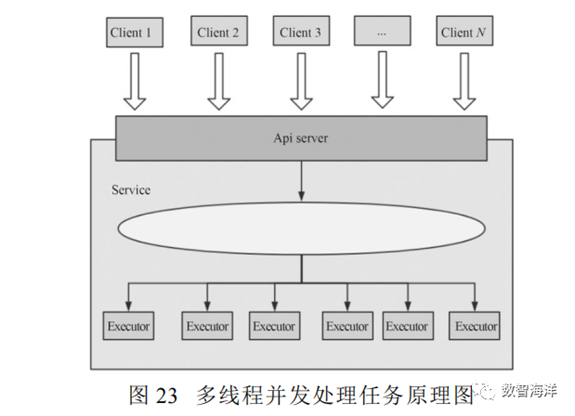
2)并发多线程处理任务
数据分析服务后端对于高并发的接口访问请求会启动多线程去处理任务作业,每一个线程都会处理一个访问请求生成的任务。在内存等硬件资源足够情况下,线程数足够支持高并发访问接口产生的任务,这些线程将按照顺序拿到CPU资源执行。原理如图23所示。
3)弹性资源调度机制
使用YARN资源调度器,通过队列、优先级设置以及资源分配原则对资源分配进行管理。
06 结 语
本文构建了一种海洋大数据智能分析系统,该系统具有如下优势特征:
1)多源异构引接汇聚子系统具有可扩展性,子中心数量、数据种类都可以扩展;
2)海洋领域行业分析子系统包括船舶装备和航行信息保障行业分析模型模板、水下装备环境适应性保障行业分析模型模板、海洋信息综合保障行业分析模型模板、风力发电综合保障行业分析模型模板,并且行业分析模板具有可扩展性,领域分析算法可以进一步进行扩充集成,同一算法可具备多个版本;
3)领域自助建模工作跟外部应用访问可无缝衔接,领域构建的特定模型保存在领域分析子系统中,外部应用系统直接可以授权共享方式请求模型访问分析并获得执行结果;
4)所有海洋领域数据和分析算法,外部应用可以在源代码中通过API接口调用发生进行访问,降低应用访问难度。




